

Cos’è l’OCR e come si è evoluto: dalle tecniche tradizionali ai Vision Language Model
L’OCR converte testi da immagini e PDF in contenuti digitali, ma oggi è solo il primo passo. Con VLM e IDP, i sistemi evoluti non si limitano a leggere: comprendono i documenti, strutturano i dati e abilitano l’automazione.
L'OCR (Optical Character Recognition) è una tecnologia che consente di convertire testi presenti in immagini o PDF scannerizzati in contenuti digitali modificabili e ricercabili. È una delle tecnologie più utilizzate nei processi di digitalizzazione documentale. Nel contesto attuale dell'Intelligent Document Processing rappresenta però solo il primo passo verso sistemi più avanzati di comprensione e automazione.
Cos’è l’OCR
L'OCR è un sistema in grado di riconoscere caratteri all'interno di un'immagine e trasformarli in testo digitale.
In pratica, permette di:
- estrarre testo da documenti cartacei digitalizzati
- rendere ricercabili PDF e immagini
- convertire contenuti non strutturati in formato testuale
Un esempio semplice: scattando una foto a una fattura, un sistema OCR è in grado di leggere il testo e restituirlo in formato digitale. Il modo in cui lo fa, però, cambia radicalmente a seconda della generazione tecnologica che stiamo considerando.
Come funziona l’OCR
Ogni sistema OCR, indipendentemente dall'approccio, percorre una serie di passaggi fondamentali che trasformano un'immagine in testo leggibile dalla macchina.
Acquisizione dell’immagine
Ogni sistema OCR segue una serie di passaggi fondamentali che trasformano un’immagine in testo leggibile dalla macchina.
1. Acquisizione dell’immagine
Il processo parte da un input visivo, come una scansione, una fotografia o un PDF.
2. Pre-elaborazione
L’immagine viene ottimizzata per migliorare la leggibilità:
- rimozione del rumore
- miglioramento del contrasto
- correzione dell’inclinazione (deskewing)
3. Segmentazione
Il sistema individua e separa righe di testo, parole e caratteri.
Questa fase è cruciale: una segmentazione imprecisa compromette tutto il processo.
4. Riconoscimento dei caratteri
Il sistema analizza forme e pattern visivi per identificare lettere e numeri.
5. Generazione dell’output
Il risultato finale è un testo digitale modificabile, copiabile e indicizzabile.
L'evoluzione tecnica dell'OCR: dalle regole manuali ai modelli neurali
Questa è la parte che più è cambiata negli ultimi decenni. Comprendere l'evoluzione aiuta a capire perché i sistemi moderni sono così più robusti rispetto alle prime implementazioni — e perché i VLM rappresentano un salto di natura diversa rispetto ai miglioramenti precedenti.
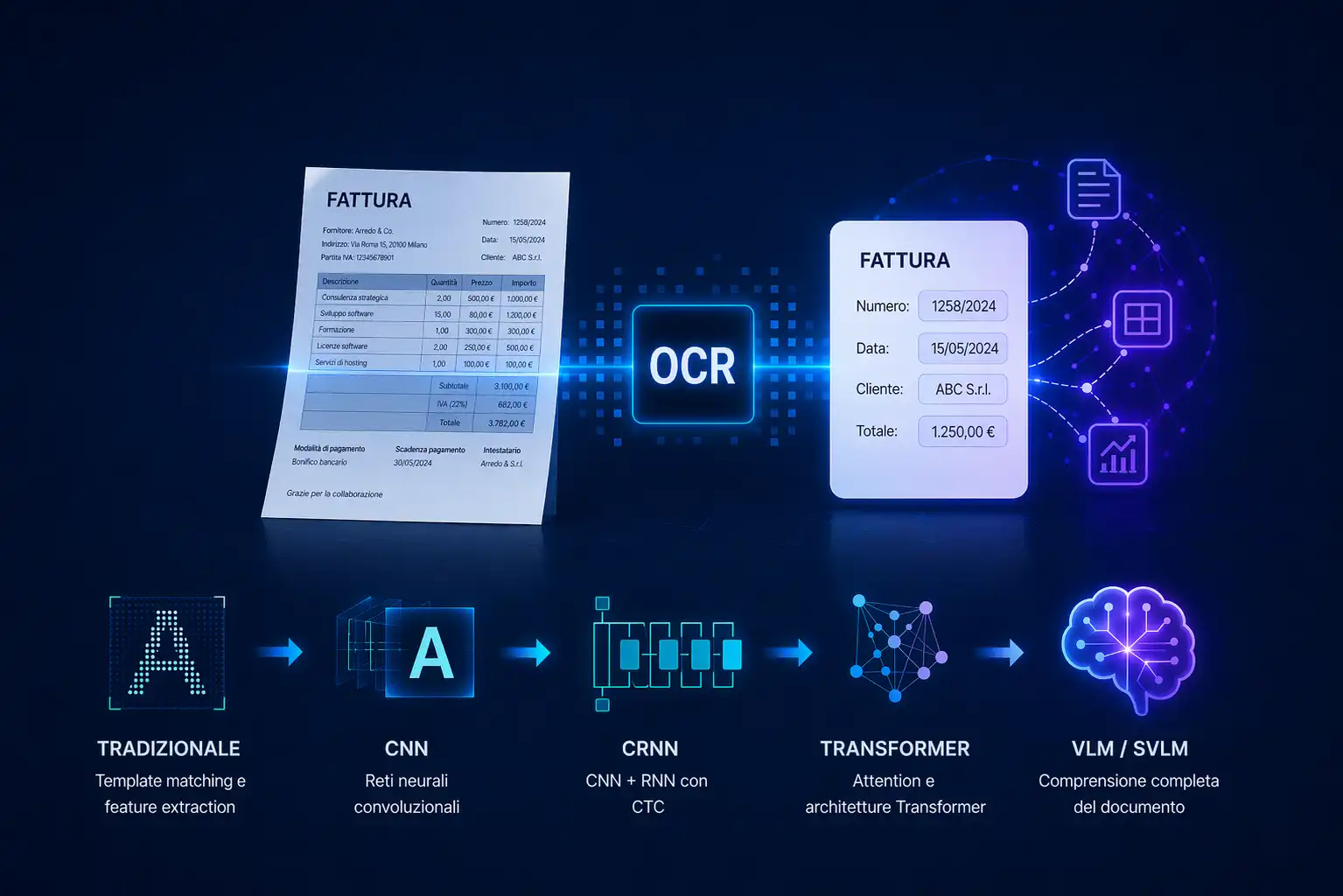
OCR tradizionale: template matching e feature extraction
I primi sistemi OCR funzionavano per confronto diretto: ogni carattere rilevato veniva confrontato con un insieme di template predefiniti (uno per ogni lettera dell'alfabeto, maiuscola e minuscola, in ogni font supportato). Il carattere veniva assegnato alla classe con la maggiore sovrapposizione visiva. Il limite era evidente: bastava un font diverso, un'inclinazione minima o una scansione di qualità mediocre per far crollare l'accuratezza. Una versione più sofisticata utilizzava la feature extraction manuale: invece di confrontare pixel per pixel, si estraevano caratteristiche geometriche come proporzioni, rapporti tra altezza e larghezza, presenza di aste ascendenti o discendenti, angoli delle curve. Tecniche come HOG (Histogram of Oriented Gradients) e la proiezione dei profili erano comuni in questo approccio. Il problema rimaneva lo stesso: le feature erano definite a mano da ingegneri, e non generalizzavano bene al di fuori dei casi previsti in fase di progettazione.
Reti neurali convoluzionali (CNN)
L'introduzione delle reti neurali convoluzionali ha segnato una svolta. A differenza dei sistemi tradizionali, una CNN apprende automaticamente le feature rilevanti dai dati di training, senza che nessuno debba definirle manualmente. Applicata all'OCR, una CNN riceve in input una porzione di immagine — un singolo carattere nei sistemi con segmentazione esplicita, oppure un'intera parola o riga nei sistemi più avanzati — e produce in output una distribuzione di probabilità sulle classi possibili (lettere, numeri, simboli). La granularità dell'input dipende quindi dall'approccio di segmentazione adottato a monte. Le reti profonde si sono dimostrate molto più robuste alle variazioni di font, qualità dell'immagine e stile di scrittura rispetto ai metodi precedenti. Il limite rimasto è la dipendenza da una segmentazione preventiva affidabile: nei sistemi carattere per carattere, la rete deve prima sapere con precisione dove inizia e dove finisce ogni carattere nella riga.
Sistemi ibridi CNN + RNN (CRNN)
Il passo successivo è stato eliminare la dipendenza da una segmentazione perfetta. I sistemi CRNN (Convolutional Recurrent Neural Network) combinano:
Questi combinano:
- una CNN per estrarre feature visive dall'immagine di una riga di testo intera
- una RNN (tipicamente una LSTM bidirezionale) per modellare le dipendenze sequenziali tra i caratteri
La rete elabora la riga come sequenza di colonne di feature e produce una sequenza di predizioni. Queste vengono poi decodificate tramite la CTC loss (Connectionist Temporal Classification), un algoritmo che permette di allineare le predizioni con il testo target senza richiedere che ogni carattere sia pre-segmentato.
Questo approccio ha reso l'OCR molto più robusto su testi manoscritti, font inusuali e documenti con spaziatura irregolare
Transformer e attention mechanism
Più recentemente, i meccanismi di attention e le architetture Transformer sono stati applicati anche all'OCR. Modelli come TrOCR di Microsoft combinano un encoder visivo basato su Vision Transformer (ViT) con un decoder Transformer per la generazione del testo.
Il vantaggio è la capacità di catturare dipendenze a lungo raggio — sia visive che linguistiche — in modo molto più flessibile rispetto alle LSTM. Questi modelli ottengono risultati allo stato dell'arte su benchmark di testo manoscritto e stampato, ma il loro obiettivo rimane la trascrizione del testo: non interpretano il documento nel suo insieme.
OCR vs Vision Language Model (VLM e SVLM): un cambio di paradigma
Con l'emergere dei Vision Language Model (VLM) e delle loro versioni più compatte, i Small Vision Language Model (SVLM), si è verificato un cambiamento architetturale profondo che va ben oltre il miglioramento delle prestazioni.
La differenza fondamentale non è solo nel livello di accuratezza: è nel modo in cui il problema viene affrontato.
Confronto diretto
Cosa fanno i Vision Language Model
Un VLM non esegue OCR come step separato: processa direttamente l'immagine del documento e può essere istruito per svolgere task specifici — trascrizione del testo, analisi del layout, estrazione di entità, risposta a domande sul contenuto ("qual è il totale della fattura?", "chi è il mittente?", "estrai le righe della tabella") — senza dover prima convertire l'immagine in testo grezzo.
Questo cambia completamente il paradigma: invece di orchestrare una sequenza di step specializzati (segmentazione, riconoscimento, post-processing, estrazione), si dispone di un unico modello end-to-end in grado di gestire tutta la complessità del documento in modo integrato
Gli SVLM analizzano simultaneamente:
- il layout visivo del documento
- le relazioni spaziali tra gli elementi
- il contesto semantico delle informazioni
Il risultato è un sistema capace non solo di leggere il testo, ma di capire cosa quel testo rappresenta all'interno del documento — un salto qualitativo che le pipeline OCR tradizionali, anche le più sofisticate, non riescono a compiere.
OCR e Intelligent Document Processing (IDP): l'OCR come uno step tra tanti
Per comprendere il ruolo dell'OCR nei sistemi aziendali reali, è utile inquadrarlo all'interno del concetto più ampio di Intelligent Document Processing (IDP).
In una pipeline IDP, l'OCR rappresenta tipicamente il primo step — quello che trasforma l'immagine in testo grezzo — ma da solo non è sufficiente a produrre valore. Il testo estratto deve essere poi:
- classificato (che tipo di documento è?)
- analizzato strutturalmente (dove si trovano i campi rilevanti?)
- interpretato semanticamente (cosa significa quel valore in quel contesto?)
- validato e integrato nei sistemi aziendali a valle
Tutto ciò che sta dopo l'OCR richiede logiche aggiuntive: regole, modelli di classificazione, espressioni regolari, o — nei sistemi più moderni — modelli di linguaggio e visione artificiale. Questo è il motivo per cui l'OCR puro tende a essere fragile in produzione: funziona bene nel caso ideale, ma ogni variazione di layout, qualità o formato richiede interventi manuali sulla pipeline. Nei sistemi IDP basati su VLM o SVLM, invece, molti di questi step vengono collassati in un unico modello, riducendo la complessità operativa e aumentando la robustezza su documenti reali e variabili.
Quando usare l'OCR e quando serve qualcosa di più avanzato
L'OCR è la scelta giusta quando l'obiettivo è:
- digitalizzare documenti e renderli ricercabili
- estrarre testo grezzo in modo posizionale e scalabile
- lavorare su documenti con struttura fissa e prevedibile
Tuttavia, quando è necessario:
- comprendere il significato del documento
- estrarre dati strutturati da layout variabili
- automatizzare processi decisionali a valle
l'OCR da solo non è sufficiente. In questi casi è necessario adottare un approccio IDP più completo, con modelli multimodali o VLM al centro della pipeline.
Conclusione: l'OCR è solo l'inizio
L'OCR ha percorso una strada lunga — dai template rigidi degli anni '80 alle architetture Transformer moderne — e resta una tecnologia fondamentale nella digitalizzazione dei documenti.
Ma nel contesto attuale, non è più sufficiente da solo per rispondere alle esigenze aziendali. Le organizzazioni hanno bisogno di sistemi in grado di comprendere e interpretare i documenti, non solo di leggerli.
L'evoluzione verso l'Intelligent Document Processing e i Vision Language Model non è una sostituzione dell'OCR: è la sua naturale maturazione verso sistemi capaci di ragionare sul contenuto, non solo di trascriverlo.
Il ruolo di myBiros nell'evoluzione dell'OCR
In myBiros utilizziamo l'OCR come punto di partenza, integrandolo con tecnologie di computer vision e Small Vision Language Model (SVLM) per ottenere una comprensione completa dei documenti.
Questo approccio permette di:
- analizzare la struttura visiva dei documenti (layout, campi, tabelle)
- interpretare il contenuto nel contesto corretto
- estrarre dati strutturati in modo automatico
- ridurre la necessità di regole manuali e pipeline fragili
L'obiettivo di myBiros è trasformare documenti non strutturati in dati affidabili e pronti per essere utilizzati all'interno di ERP, CRM e sistemi aziendali.
Vuoi capire come applicare queste tecnologie ai tuoi flussi documentali?
Contattaci o prenota una demo di myBiros.
Articoli correlati

Oltre la Demo: le complessità nascoste nell’addestrare e validare VLMs per la Document AI
Addestrare un VLM per la Document AI può sembrare semplice in demo, ma portarlo in produzione richiede una pipeline robusta: dataset multimodali, fine-tuning controllato e validazione affidabile degli output.
Leggilo ora
Make or Buy nell’IDP: come scegliere l’automazione documentale giusta
Sviluppare o acquistare una piattaforma IDP? Una guida pratica per valutare costi, tempi, scalabilità e rischi nella scelta della migliore soluzione di automazione documentale.
Leggilo ora
OCR vs IDP: differenze e quale tecnologia scegliere
OCR e IDP sono due tecnologie chiave per l’automazione documentale: l’OCR permette di leggere il testo da immagini e PDF, mentre l’IDP comprende il contenuto dei documenti e lo trasforma in dati strutturati pronti per i processi aziendali.
Leggilo ora
Cos'è la Document AI? Evoluzione negli anni e task principali
La Document AI rappresenta l’evoluzione delle tecnologie per comprendere, classificare, estrarre e generare dati dai documenti. L’articolo analizza il passaggio dai sistemi rule-based ai modelli multimodali e il valore delle piattaforme IDP
Leggilo ora
Cos'è l'intelligenza artificiale e perché è importante per le aziende
L’intelligenza artificiale aiuta le imprese ad automatizzare attività, analizzare dati, gestire documenti e rendere più efficienti i processi. In questo articolo vediamo cos’è l’AI, come funziona e dove può generare valore reale in azienda.
Leggilo oraCos’è l’OCR e come si è evoluto: dalle tecniche tradizionali ai Vision Language Model
L’OCR converte testi da immagini e PDF in contenuti digitali, ma oggi è solo il primo passo. Con VLM e IDP, i sistemi evoluti non si limitano a leggere: comprendono i documenti, strutturano i dati e abilitano l’automazione.
Leggilo ora

.svg)
.svg)
