

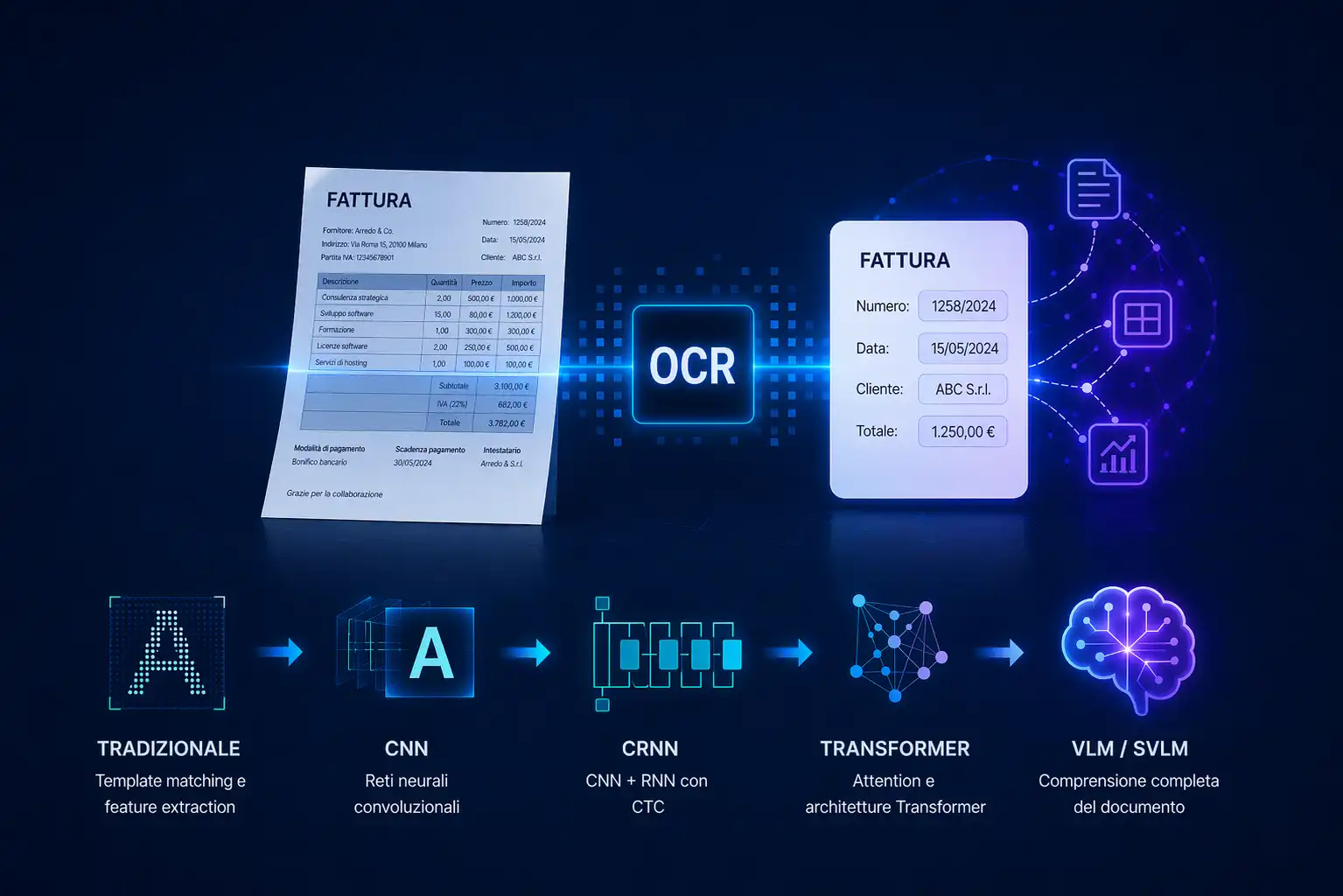
What is OCR and how has it evolved: from traditional techniques to Vision Language Models
OCR converts text from images and PDFs into digital content, but today it's only the first step. With VLM and IDP, advanced systems don't just read: they understand documents, structure data and enable automation.
OCR (Optical Character Recognition) is a technology that allows you to convert text in scanned images or PDFs into editable and searchable digital content. It is one of the most used technologies in document digitization processes. In the current context, Intelligent Document Processing, however, represents only the first step towards more advanced understanding and automation systems.
What is OCR
OCR is a system capable of recognizing characters within an image and transforming them into digital text.
In practice, it allows you to:
- extract text from scanned paper documents;
- make PDFs and images searchable;
- convert unstructured content to text format.
A simple example: by taking a photo of an invoice, an OCR system is able to read the text and return it in digital format. The way in which it does it, however, changes radically depending on the technological generation we are considering.
How does OCR work
Every OCR system, regardless of the approach, goes through a series of fundamental steps that transform an image into machine-readable text.
Acquiring the image
Every OCR system follows a series of fundamental steps that transform an image into machine-readable text.
1. Acquiring the image
The process starts with visual input, such as a scan, photo, or PDF.
2. Pre-processing
The image is optimized to improve readability:
- noise removal;
- contrast enhancement;
- inclination correction (deskewing).
3. Segmentation
The system identifies and separates lines of text, words, and characters. This phase is crucial: imprecise segmentation compromises the entire process.
4. Character recognition
The system analyzes visual shapes and patterns to identify letters and numbers.
5. Output generation
The final result is editable, copyable and indexable digital text.
The technical evolution of OCR: from manual rules to neural models
This is the part that has changed the most in recent decades. Understanding evolution helps to understand why modern systems are so more robust than the first implementations — and why VLMs represent a leap of a different nature compared to previous improvements.
Traditional OCR: template matching and feature extraction
The first OCR systems worked by direct comparison: each detected character was compared with a set of predefined templates (one for each letter of the alphabet, uppercase and lowercase, in each supported font). The character was assigned to the class with the most visual overlap. The limit was obvious: a different font, a minimum inclination or a mediocre quality scan was enough to reduce accuracy. A more sophisticated version used manual feature extraction: instead of comparing pixel by pixel, geometric characteristics such as proportions, relationships between height and width, presence of ascenders and descenders, angles of curves were extracted. Techniques such as HOG (Histogram of Oriented Gradients) and profile projection were common in this approach. The problem remained the same: the features were defined by hand by engineers, and they did not generalize well outside the cases foreseen during the design phase.
Convolutional Neural Networks (CNN)
The introduction of convolutional neural networks marked a turning point. Unlike traditional systems, a CNN automatically learns relevant features from training data, without anyone having to define them manually. Applied to OCR, a CNN receives as input a portion of an image — a single character in systems with explicit segmentation, or an entire word or line in the most advanced systems — and produces in output a probability distribution over the possible classes (letters, numbers, symbols). The granularity of the input therefore depends on the segmentation approach adopted upstream. Deep networks have proven to be much more robust to variations in font, image quality, and writing style than previous methods. The remaining limit is the dependence on reliable prior segmentation: in character-by-character systems, the network must first know precisely where each character in the line begins and ends.
CNN + RNN (CRNN) hybrid systems
The next step was to eliminate the dependency on perfect segmentation. CRNN (Convolutional Recurrent Neural Network) systems combine:
These combine:
- a CNN to extract visual features from the image of an entire line of text;
- an RNN (typically a bidirectional LSTM) to model sequential dependencies between characters.
The network processes the line as a sequence of feature columns and produces a sequence of predictions. These are then decoded using CTC loss (Connectionist Temporal Classification), an algorithm that allows the predictions to be aligned with the target text without requiring that each character be pre-segmented.
This approach has made OCR much more robust on handwritten text, unusual fonts, and irregularly spaced documents
Transformer and attention mechanism
More recently, attention mechanisms and Transformer architectures have also been applied to OCR. Models like Microsoft's TroCR combine a visual encoder based on Vision Transformer (ViT) with a Transformer decoder for text generation.
The benefit is the ability to capture long-range dependencies — both visual and linguistic — in a much more flexible way than LSTMs. These models obtain state-of-the-art results on handwritten and printed text benchmarks, but their goal remains the transcription of the text: they do not interpret the document as a whole.
OCR vs Vision Language Models (VLMs and SVLMs): a paradigm shift
With the emergence of Vision Language Models (VLMs) and their more compact versions, Small Vision Language Models (SVLMs), a profound architectural change has occurred that goes far beyond improving performance.
The fundamental difference is not only in the level of accuracy: it is in the way in which the problem is addressed.
Direct comparison
What do Vision Language Models do
A VLM does not perform OCR as a separate step: Process the document image directly and can be instructed to perform specific tasks — transcribing the text, analyzing the layout, extracting entities, answering questions about the content (“what is the total of the invoice?” , “who's the sender?” , “extract table rows”) — without having to convert the image to raw text first.
This completely changes the paradigm: instead of orchestrating a sequence of specialized steps (segmentation, recognition, post-processing, extraction), you have a single end-to-end model capable of managing all the complexity of the document in an integrated way
SVLMs simultaneously analyze:
- the visual layout of the document;
- spatial relationships between elements;
- the semantic context of information;
The result is a system capable not only of reading the text, but of understanding what that text represents within the document — a qualitative leap that traditional OCR pipelines, even the most sophisticated, are unable to make.
OCR and Intelligent Document Processing (IDP): OCR as one step in a broader process
To understand the role of OCR in real business systems, it is useful to frame it within the broader concept of Intelligent Document Processing (IDP).
In an IDP pipeline, OCR is typically the first step — the one that transforms the image into raw text — but on its own it's not enough to produce value. The extracted text must then be:
- classified (what type of document is it?);
- structurally analyzed (where are the relevant fields located?);
- interpreted semantically (what does that value mean in that context?);
- validated and integrated into downstream business systems.
Everything after OCR requires additional logic: rules, classification models, regular expressions, or — in more modern systems — language and computer vision models. This is why pure OCR tends to be fragile in production: it works well in the ideal case, but any variation in layout, quality, or format requires manual intervention on the pipeline. In IDP systems based on VLM or SVLM, however, many of these steps are collapsed into a single model, reducing operational complexity and increasing robustness on real and variable documents.
When to use OCR and when you need something more advanced
OCR is the right choice when the goal is:
- digitize documents and make them searchable;
- extract raw text in a positional and scalable way;
- work on documents with a fixed and predictable structure;
However, when you need to:
- understand the meaning of the document;
- extract structured data from variable layouts;
- automate decision-making processes downstream;
OCR alone is not enough. In these cases, it is necessary to adopt a more comprehensive IDP approach, with multimodal or VLMs at the center of the pipeline.
The role of MyBiros in the evolution of OCR
At MyBiros we use OCR as a starting point, integrating it with Computer Vision technologies and Small Vision Language Models (SVLMs) to get a full understanding of the documents.
This approach allows you to:
- analyze the visual structure of documents (layout, fields, tables);
- interpret the content in the correct context;
- extract structured data automatically;
- reduce the need for manual rules and fragile pipelines.
The goal of MyBiros is to transform unstructured documents into reliable data ready to be used within ERP, CRM and business systems.
Conclusion: OCR is just the beginning
OCR has come a long way — from the rigid templates of the 80s to modern Transformer architectures — and remains a fundamental technology in the digitization of documents.
But in today's environment, it's no longer enough on its own to meet business needs. Organizations need systems that can understand and interpret documents, not just to read them.
The evolution towards Intelligent Document Processing and the Vision Language Model is not a replacement for OCR: it is its natural maturation towards systems capable of reasoning over the content, not just transcribing it.
Articles in the same category

Beyond the Demo: The Hidden Complexities of Training and Validating VLMs for Document AI
Training a VLM for Document AI may look straightforward in a demo, but bringing it into production requires a robust pipeline: multimodal datasets, controlled fine-tuning, and reliable output validation.
Read it now
Make or buy in IDP: how to choose the right document automation solution
Build or buy an IDP platform? a practical guide to assessing costs, timelines, scalability, and risks when choosing the best document automation solution.
Read it now
OCR vs IDP: differences and which technology to choose
OCR and IDP are two key technologies for document automation: OCR makes it possible to read text from images and PDFs, while IDP understands document content and transforms it into structured data ready for business processes.
Read it now
What Is Document AI? Its Evolution Over the Years and Main Tasks
Document AI represents the evolution of technologies designed to understand, classify, extract, and generate data from documents, from rule-based systems to multimodal models and complete IDP platforms.
Read it now
What is artificial intelligence and why is it important for businesses
Artificial intelligence helps businesses automate tasks, analyze data, manage documents, and make processes more efficient. In this article, we explore what AI is, how it works, and where it can generate real value within a company.
Read it nowWhat is OCR and how has it evolved: from traditional techniques to Vision Language Models
OCR converts text from images and PDFs into digital content, but today it's only the first step. With VLM and IDP, advanced systems don't just read: they understand documents, structure data and enable automation.
Read it now

.svg)
.svg)
