


Small Vision Language Models (SVLM): what they are and why they are transforming document processing
Small Vision Language Models (SVLM) are artificial intelligence models capable of simultaneously processing visual and textual content. Born as a compact evolution of generalist VLMo, they are used in numerous domains.
Small Vision Language Models (SVLMs) are artificial intelligence models capable of processing visual and textual content simultaneously. Developed as a compact evolution of general-purpose Vision Language Models, they are used in numerous domains, from robotics to medical image analysis, but prove particularly effective in enterprise document processing, where the joint understanding of layout and text is a fundamental requirement.
In recent years, document processing has undergone a profound transformation thanks to the evolution of artificial intelligence.
Traditional systems, based on OCR rules have represented the state of the art for years, but they show obvious limits when it comes to understanding the structure, context and meaning of a document. Today, thanks to models capable of simultaneously processing visual and textual content, these limitations can be overcome in a concrete way.
It is in this context that the Small Vision Language Models (SVLM) are attracting increasing attention. These are not models created specifically for documents, but their characteristics, multimodal capacity, compactness, adaptability, make them particularly suitable for this domain, especially in business environments where precision, speed and sustainable costs are needed.
What are SVLM (Small Vision Language Models)
SVLMs are multimodal models capable of simultaneously processing:
- visual information (layout, structure, graphic elements)
- textual content (meaning, context, relationships)
This means that, in the context of document processing, they do not just read the text of a document, but analyze its structure and content in an integrated way, to return more accurate and contextualized data.
Vision component
The visual component allows you to analyze:
- arranging text blocks
- tables and fields
- headings and sections
- spatial relationships between elements
Language component
The linguistic component allows you to:
- Interpret the meaning of the data
- identify relevant information
- understand the documentary context
This is fundamental in business documents, where the value is not in the text itself, but in its correct interpretation.
What does small mean
The term 'small' does not indicate a limitation, but a design choice.
SVLMs are models:
- more compact than LLMs (they have a reduced number of parameters)
- adaptable through fine-tuning to specific domains in an efficient way
- designed for production environments with low hardware resources
In many cases, they are more effective than larger models precisely because compactness favors more predictable behavior and lower latencies, critical characteristics in real business environments.
Why SVLMs are getting attention
In real document processing, companies face concrete needs: large volumes of documents, fast response times, sustainable costs and the need for integration into existing systems.
In this context, large generalist models are not always the right choice — they are often oversized, expensive and difficult to control in production.
SVLMs offer a better balance between accuracy, speed, and computational efficiency. But perhaps the most underestimated benefit is the controllability: more compact models tend to produce more predictable and consistent outputs, a critical characteristic when extracted data feeds downstream business systems.
Generalist SVLM vs LLM: the advantage of compact models
Not all AI models are equally suited to documents.
Generalist Large Language Models are extremely powerful, but in document processing contexts they have concrete limitations: they tend to be oversized for structured tasks, have high inference costs and produce less predictable outputs, a critical problem when the extracted data must feed business systems.
SVLMs, thanks to their more compact architecture and the possibility of being adapted through fine-tuning, offer practical advantages:
- greater precision in extracting data on specific domains
- better understanding of the document layout
- more consistent and structured output
- more stable and reliable behavior in repetitive flows
When the goal is to extract reliable data in production, compactness and adaptability become determining factors, often more than raw power.
Difference between OCR, multimode models, and SVLM
To understand the role of SVLMs, it is useful to compare them with the most common technologies.
Traditional OCR
- Convert images to text
- does not include the content nor the layout
- requires additional logic to extract structured data
Large multimodal models
- advanced reasoning and understanding skills
- high flexibility on heterogeneous tasks
- high inference costs and operational complexity
SVLM
- they process text and visual structure in an integrated way
- more computationally efficient
- more predictable and consistent outputs
- adaptable through fine-tuning to specific domains and document types
SVLMs are not a compromise solution, but a precise design choice: they privilege efficiency, adaptability and predictability over generalist flexibility, characteristics that often make the difference in production.
The role of SVLMs in document processing
A modern document processing pipeline requires tackling distinct problems in sequence: classifying the input document, identifying relevant fields, interpreting the layout, and returning structured data ready for business systems.
SVLMs can be integrated throughout the pipeline, contributing to each of these phases:
- automatic classification Incoming documents
- key-value extraction from structured and semi-structured fields
- interpretation of the layout in documents with variable structure
- contextual understanding of the content, reducing errors and ambiguities
The value is not in using them as an isolated tool, but in integrating them into a flow designed to transform raw documents into reliable and usable data.
Reduction of hallucinations and greater reliability
One of the most critical problems in generalist models is the tendency to generate information not present in the document — so-called 'hallucinations'. In a document processing context, where extracted data feeds business systems, this is an unacceptable risk.
SVLMs, thanks to their compact architecture and the possibility of being adapted through fine-tuning, tend to produce more deterministic outputs: they focus on extracting what is present in the document, limiting the free generation typical of generalist models.
The practical result is greater reliability of the extracted data, a determining factor when the accuracy and quality of the data are not negotiable.
Customization for business use cases
Another key element is the ability to adapt SVLMs to specific contexts.
They can be optimized for:
- vertical domains (finance, HR, insurance)
- specific document types
- company owner data
This makes it possible to build tailor-made solutions, much more effective than generalist models.
Predictable performance and scalability
In business settings, predictability isn't a nice-to-have, it's a requirement. A system that produces unstable outputs or with varying latencies is unlikely to hold up in production.
SVLMs, thanks to their compact architecture, offer reduced inference times, lower computational costs and more stable behavior over time. These characteristics make them suitable for enterprise environments with high-volume pipelines, where reliability and scalability must go hand in hand.
The limitations of SVLMs
It would be wrong to ignore the limits. Compared to generalist models, SVLMs offer less flexibility on heterogeneous tasks and require a well-defined application context to express their potential.
The key point is that the value does not depend only on the model, but on the overall architecture in which it is inserted. To achieve concrete results, accurate flow design, validation systems, error management and integration with existing business systems are necessary. An SVLM without a pipeline structured around it is simply a component without context.
SVLM and the future of Intelligent Document Processing
Document processing is evolving towards systems capable of understanding documents in an increasingly complete way, not only the text, but the structure, layout and semantic context in which the information appears.
In this scenario, SVLMs represent a concrete direction: efficient, adaptable and production-oriented models, which can be integrated into real pipelines without the costs and complexity of large generalist models. The goal is not to use the most powerful model, but the one that best suits the problem. and this distinction, in the enterprise environment, makes all the difference.
Bring SVLM into your document streams with MyBiros
At MyBiros, we offer a proprietary Intelligent Document Processing platform based on SVLM fine-tuned on specific domains, designed to classify documents, extract data and integrate into existing business systems. We support customers with dedicated training to ensure autonomy in configuration and management over time.
The goal is not to adopt technology in isolation, but to build a reliable and scalable system around your real documents.
Do you want to understand how to apply these technologies to your document flows?
Contact us or book a demo by MyBiros.
Articles in the same category
Make or buy in IDP: how to choose the right document automation solution
Build or buy an IDP platform? a practical guide to assessing costs, timelines, scalability, and risks when choosing the best document automation solution.
Read it now
OCR vs IDP: differences and which technology to choose
OCR and IDP are two key technologies for document automation: OCR makes it possible to read text from images and PDFs, while IDP understands document content and transforms it into structured data ready for business processes.
Read it now
What Is Document AI? Its Evolution Over the Years and Main Tasks
Document AI represents the evolution of technologies designed to understand, classify, extract, and generate data from documents, from rule-based systems to multimodal models and complete IDP platforms.
Read it now
What is artificial intelligence and why is it important for businesses
Artificial intelligence helps businesses automate tasks, analyze data, manage documents, and make processes more efficient. In this article, we explore what AI is, how it works, and where it can generate real value within a company.
Read it now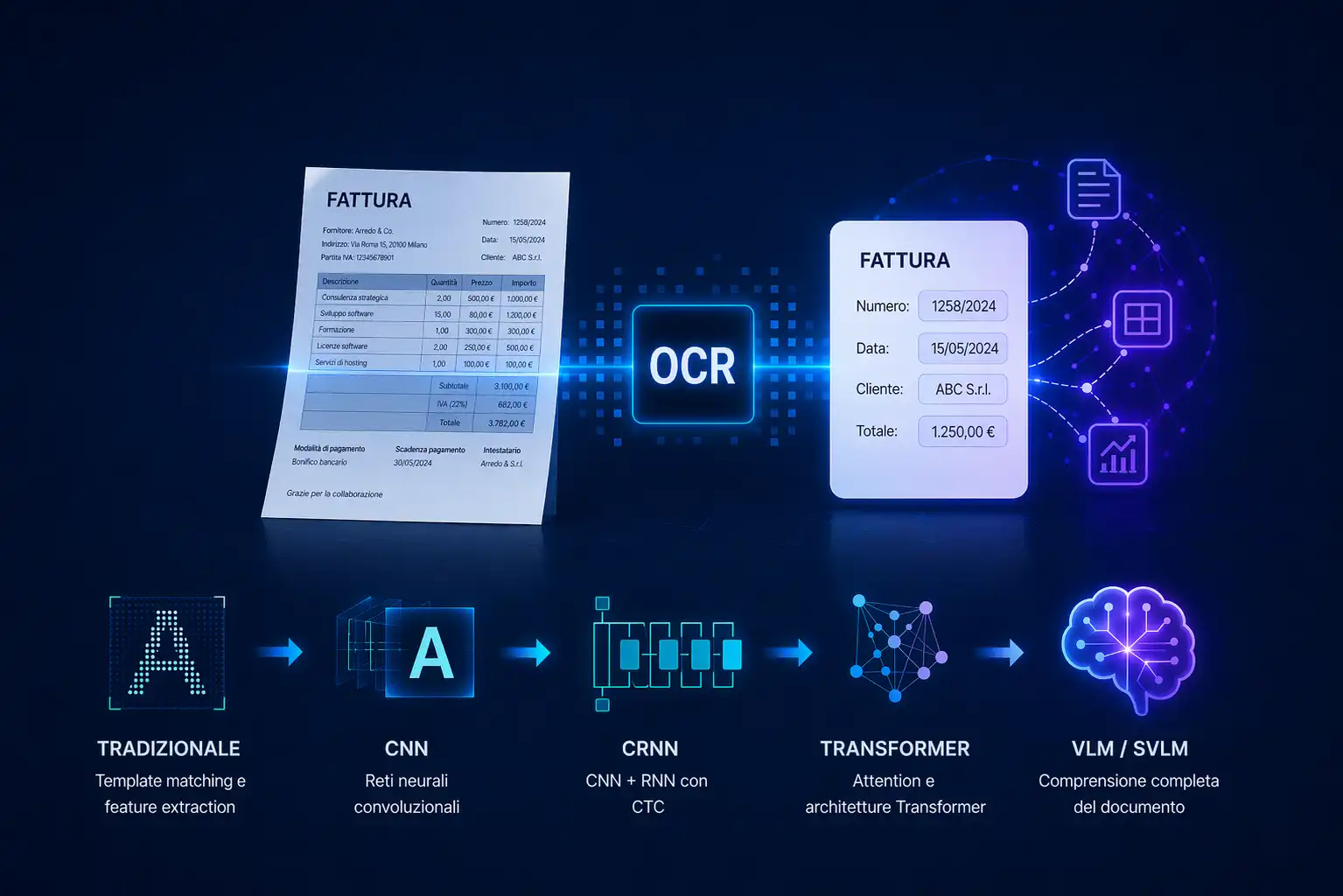
What is OCR and how has it evolved: from traditional techniques to Vision Language Models
OCR converts text from images and PDFs into digital content, but today it's only the first step. With VLM and IDP, advanced systems don't just read: they understand documents, structure data and enable automation.
Read it nowSmall Vision Language Models (SVLM): what they are and why they are transforming document processing
Small Vision Language Models (SVLM) are artificial intelligence models capable of simultaneously processing visual and textual content. Born as a compact evolution of generalist VLMo, they are used in numerous domains.
Read it now

.svg)
.svg)
