


OCR vs IDP: differenze e quale tecnologia scegliere
OCR e IDP sono due tecnologie chiave per l’automazione documentale: l’OCR permette di leggere il testo da immagini e PDF, mentre l’IDP comprende il contenuto dei documenti e lo trasforma in dati strutturati pronti per i processi aziendali.
Nel contesto della digitalizzazione documentale, OCR e IDP sono due tecnologie spesso citate insieme, ma non equivalenti.
L’OCR, o Optical Character Recognition, consente di convertire testi presenti in immagini, scansioni o PDF in contenuti digitali modificabili e ricercabili. È una tecnologia fondamentale nei processi di digitalizzazione, ma rappresenta solo il primo livello dell’elaborazione documentale.
L’IDP, o Intelligent Document Processing, è invece un approccio più avanzato: combina OCR, Intelligenza Artificiale, Computer Vision, Machine Learning e NLP per leggere, comprendere, classificare, validare ed estrarre informazioni dai documenti.
La differenza principale è semplice: l’OCR legge il testo, l’IDP comprende il documento e trasforma le informazioni in dati strutturati utilizzabili dai processi aziendali.
Cos’è l’OCR
L’OCR è una tecnologia che permette di riconoscere caratteri all’interno di un’immagine e trasformarli in testo digitale.
In pratica, consente di:
- estrarre testo da documenti cartacei digitalizzati;
- rendere ricercabili PDF e immagini;
- convertire scansioni e fotografie in contenuti testuali;
- ridurre una parte dell’inserimento manuale dei dati;
- creare archivi documentali più accessibili.
Un esempio semplice: se un’azienda riceve una scansione di una fattura, un sistema OCR può leggere il testo presente nel documento e restituirlo in formato digitale.
Questo consente di copiare, cercare, indicizzare o archiviare il contenuto. Tuttavia, il risultato rimane principalmente una trascrizione del testo.
L’OCR non è progettato per capire in modo completo cosa rappresentano quei dati nel contesto del documento.
Come funziona l’OCR
Un sistema OCR segue generalmente una serie di passaggi tecnici che trasformano un’immagine in testo leggibile dalla macchina.
Il processo parte dall’acquisizione dell’immagine, che può provenire da una scansione, una fotografia o un PDF.
Successivamente viene eseguita una fase di pre-elaborazione, utile a migliorare la qualità dell’immagine. In questa fase possono essere applicate tecniche come:
- rimozione del rumore;
- miglioramento del contrasto;
- correzione dell’inclinazione;
- normalizzazione della risoluzione;
- ottimizzazione della leggibilità.
Dopo la pre-elaborazione, il sistema individua le aree di testo, separa righe, parole o caratteri e procede con il riconoscimento dei caratteri.
Il risultato finale è un testo digitale, modificabile e indicizzabile.
Negli anni, l’OCR si è evoluto molto: dai sistemi basati su regole e template matching, fino alle reti neurali, ai Transformer e ai modelli più moderni. Tuttavia, anche nelle versioni più avanzate, l’obiettivo principale dell’OCR rimane la trascrizione del testo.
Il limite dell’OCR: leggere non significa comprendere
L’OCR è utile quando l’obiettivo è digitalizzare un documento, ma da solo non è sufficiente per automatizzare un processo documentale complesso.
Il suo limite principale è che trasforma l’immagine in testo, ma non interpreta il significato delle informazioni.
Per esempio, in una bolletta possono comparire molte date: data di emissione, data di scadenza, periodo di riferimento, data del pagamento. Un sistema OCR può leggere tutte queste date, ma non sempre è in grado di capire quale valore debba essere associato al campo corretto.
Lo stesso accade con fatture, buste paga, documenti d’identità, passaporti, contratti o moduli aziendali.
L’OCR può leggere il contenuto, ma spesso serve ancora un livello successivo per:
- capire il tipo di documento;
- individuare i campi rilevanti;
- interpretare il dato nel suo contesto;
- validare le informazioni estratte;
- esportare i dati verso ERP, CRM o gestionali aziendali.
Per questo motivo, nei processi aziendali reali, l’OCR è spesso solo il primo step di una pipeline più ampia.
Cos’è l’IDP
L’IDP, acronimo di Intelligent Document Processing, indica un insieme di tecnologie e soluzioni basate su Intelligenza Artificiale, Computer Vision, Machine Learning e NLP, progettate per automatizzare l’elaborazione dei documenti.
A differenza dell’OCR, l’IDP non si limita a leggere il testo.
Una soluzione IDP è in grado di:
- acquisire documenti da scansioni, PDF, immagini, email o PEC;
- migliorare la qualità del documento tramite pre-processing;
- analizzare layout, tabelle, campi, immagini e struttura visiva;
- classificare automaticamente il tipo di documento;
- estrarre informazioni chiave;
- trasformare dati non strutturati in dati strutturati;
- validare i risultati tramite confidence score e revisione umana;
- integrare i dati nei sistemi aziendali.
L’obiettivo dell’IDP è rendere le informazioni contenute nei documenti automaticamente fruibili da processi, reparti e applicativi aziendali.
OCR vs IDP: la differenza principale
La differenza tra OCR e IDP non riguarda solo il livello di accuratezza. Riguarda soprattutto il tipo di risultato prodotto.
L’OCR restituisce testo digitale.
L’IDP restituisce dati strutturati, contestualizzati e utilizzabili.
Un OCR può leggere una carta d’identità e restituire tutto il testo presente sul documento.
Un sistema IDP può riconoscere che si tratta di una carta d’identità, individuare nome, cognome, data di nascita, numero documento, data di scadenza e codice fiscale, organizzando ogni informazione nel campo corretto.
La differenza è sostanziale.
Con l’OCR ottieni una trascrizione.
Con l’IDP ottieni un dato pronto per essere usato.
OCR e IDP lavorano insieme?
Sì. OCR e IDP non sono tecnologie alternative in senso assoluto.
In molte pipeline IDP, l’OCR rappresenta il primo passaggio: trasforma l’immagine o la scansione in testo machine-readable.
Dopo questo step, entrano in gioco altri livelli tecnologici:
- analisi del layout;
- classificazione del documento;
- estrazione delle informazioni;
- validazione dei dati;
- arricchimento;
- integrazione con i sistemi aziendali.
In questo senso, l’OCR è una componente dell’IDP, ma non esaurisce il processo.
L’IDP aggiunge ciò che manca all’OCR puro: comprensione, contesto, automazione e integrazione.
Le fasi principali di una pipeline IDP
Una soluzione di Intelligent Document Processing può includere diverse fasi, a seconda del tipo di documento e del processo da automatizzare.
1. Pre-processing del documento
Il documento viene ottimizzato per migliorare la qualità dell’immagine e la leggibilità.
Questa fase può includere correzione dell’inclinazione, normalizzazione della risoluzione, miglioramento del contrasto e pulizia dell’immagine.
2. Analisi del layout
Il sistema analizza la struttura visiva del documento e individua elementi come paragrafi, intestazioni, tabelle, immagini, firme, campi e sezioni.
Questa fase è fondamentale per comprendere dove si trovano le informazioni rilevanti.
3. OCR e identificazione del testo
Il testo viene riconosciuto e trasformato in contenuto digitale.
In una pipeline IDP, però, questo non è il risultato finale, ma solo una base su cui costruire gli step successivi.
4. Classificazione del documento
Il sistema assegna automaticamente al documento una categoria.
Per esempio, può distinguere tra fattura, bolletta, carta d’identità, passaporto, busta paga, contratto o ricevuta.
La classificazione può avvenire analizzando il testo, l’immagine o entrambi.
5. Estrazione delle informazioni
Questa è una delle fasi centrali dell’IDP.
Il sistema individua ed estrae i dati utili dal documento, come importi, date, codici, nominativi, tabelle, indirizzi, numeri documento o informazioni anagrafiche.
L’obiettivo è trasformare informazioni non strutturate in dati strutturati.
6. Validazione dei risultati
Molte soluzioni IDP utilizzano un meccanismo di confidence score per indicare il livello di affidabilità dei dati estratti.
Quando il sistema rileva un dato potenzialmente incerto, può essere prevista una revisione umana.
Questo approccio, noto come Human in the Loop, consente di ridurre gli errori e migliorare il sistema nel tempo.
7. Integrazione con i sistemi aziendali
L’ultimo step è l’invio dei dati verso ERP, CRM, gestionali, sistemi HR, piattaforme documentali o workflow aziendali.
Questa fase è fondamentale perché consente di trasformare l’elaborazione del documento in un processo realmente automatizzato.
Quando usare l’OCR
L’OCR è la scelta corretta quando l’obiettivo è principalmente digitalizzare documenti e renderli ricercabili.
È adatto quando:
- i documenti sono chiari e leggibili;
- il layout è fisso o prevedibile;
- serve estrarre testo grezzo;
- non è richiesta una forte interpretazione del contenuto;
- il processo successivo può essere gestito manualmente o con regole semplici.
Esempi tipici sono la conversione di archivi cartacei, la creazione di PDF ricercabili o la lettura di documenti semplici e standardizzati.
Quando serve l’IDP
L’IDP diventa necessario quando il documento non deve solo essere letto, ma compreso ed elaborato.
È la scelta più adatta quando bisogna:
- classificare automaticamente i documenti;
- estrarre dati specifici da layout variabili;
- gestire documenti strutturati, semi-strutturati e non strutturati;
- ridurre l’intervento manuale;
- validare i dati estratti;
- integrare le informazioni nei sistemi aziendali;
- automatizzare processi documentali complessi.
L’IDP è particolarmente utile per:
- bollette;
- fatture;
- buste paga;
- carte d’identità;
- passaporti;
- contratti;
- ricevute;
- ordini di acquisto;
- richieste di rimborso;
- pratiche amministrative;
- documenti bancari o assicurativi;
- email e PEC con allegati.
OCR, VLM e IDP: l’evoluzione della comprensione documentale
Negli ultimi anni, l’evoluzione dei modelli di Intelligenza Artificiale ha portato a un cambio di paradigma.
I sistemi OCR tradizionali seguono una pipeline composta da più step separati: segmentazione, riconoscimento del testo, post-processing ed eventuale estrazione.
I modelli più moderni, come i Vision Language Model e gli Small Vision Language Model, permettono invece di analizzare simultaneamente immagine, layout e contenuto semantico del documento.
Questo consente di ridurre la dipendenza da regole manuali e pipeline fragili, soprattutto quando i documenti hanno formati variabili o qualità non perfetta.
Nel contesto IDP, queste tecnologie rendono possibile un’elaborazione più robusta, flessibile e vicina al modo in cui una persona leggerebbe e comprenderebbe un documento.
Perché l’IDP è strategico per le aziende
Le aziende gestiscono ogni giorno grandi quantità di documenti: PDF, scansioni, allegati email, PEC, moduli, fatture, contratti, documenti d’identità e pratiche operative.
Senza una soluzione intelligente, questi documenti richiedono attività manuali ripetitive: apertura del file, lettura, controllo, copia dei dati e inserimento nei sistemi aziendali.
Questo genera tempi lunghi, costi operativi, errori e difficoltà di scalabilità.
L’IDP consente di automatizzare queste attività trasformando i documenti in dati affidabili e pronti all’uso.
I principali benefici sono:
- riduzione delle attività manuali ripetitive;
- maggiore qualità dei dati;
- minore rischio di errore;
- elaborazione più veloce dei documenti;
- migliore scalabilità;
- integrazione con i sistemi aziendali;
- automazione dei processi end-to-end;
- possibilità di gestire documenti diversi con un’unica soluzione.
Il ruolo di myBiros
myBiros è una soluzione di Intelligent Document Processing progettata per automatizzare l’estrazione dati da documenti aziendali.
Utilizza tecnologie di OCR, Computer Vision e modelli avanzati di Intelligenza Artificiale per analizzare documenti strutturati, semi-strutturati e non strutturati.
Con MyBiros è possibile elaborare automaticamente documenti come:
- bollette;
- buste paga;
- carte d’identità;
- passaporti;
- fatture;
- documenti amministrativi;
- documenti custom aziendali.
L’obiettivo è trasformare documenti non strutturati in dati strutturati, affidabili e integrabili nei sistemi aziendali.
Grazie ad API pronte all’uso e alla possibilità di adattare la pipeline a casi specifici, myBiros consente di ridurre il lavoro manuale, migliorare la qualità dei dati e velocizzare l’automazione dei processi documentali.
Conclusione
L’OCR è una tecnologia fondamentale per la digitalizzazione documentale, ma oggi rappresenta solo il primo passo.
Permette di leggere il testo presente in immagini, scansioni e PDF, ma non è sufficiente quando l’obiettivo è comprendere il documento, estrarre dati specifici e automatizzare un processo aziendale.
L’IDP nasce proprio per superare questo limite.
Attraverso l’uso combinato di OCR, Computer Vision, Intelligenza Artificiale, NLP e modelli multimodali, l’Intelligent Document Processing consente di trasformare documenti complessi in dati strutturati e utilizzabili.
Per le aziende che vogliono ridurre attività manuali, aumentare la qualità dei dati e automatizzare i flussi documentali, l’IDP rappresenta la naturale evoluzione dell’OCR.
Vuoi capire come applicare l’IDP ai tuoi processi documentali?
Prenota una demo di MyBiros o contattaci e scopri come trasformare i tuoi documenti in dati pronti per ERP, CRM e sistemi aziendali.
Articoli correlati

Oltre la Demo: le complessità nascoste nell’addestrare e validare VLMs per la Document AI
Addestrare un VLM per la Document AI può sembrare semplice in demo, ma portarlo in produzione richiede una pipeline robusta: dataset multimodali, fine-tuning controllato e validazione affidabile degli output.
Leggilo ora
Make or Buy nell’IDP: come scegliere l’automazione documentale giusta
Sviluppare o acquistare una piattaforma IDP? Una guida pratica per valutare costi, tempi, scalabilità e rischi nella scelta della migliore soluzione di automazione documentale.
Leggilo oraOCR vs IDP: differenze e quale tecnologia scegliere
OCR e IDP sono due tecnologie chiave per l’automazione documentale: l’OCR permette di leggere il testo da immagini e PDF, mentre l’IDP comprende il contenuto dei documenti e lo trasforma in dati strutturati pronti per i processi aziendali.
Leggilo ora
Cos'è la Document AI? Evoluzione negli anni e task principali
La Document AI rappresenta l’evoluzione delle tecnologie per comprendere, classificare, estrarre e generare dati dai documenti. L’articolo analizza il passaggio dai sistemi rule-based ai modelli multimodali e il valore delle piattaforme IDP
Leggilo ora
Cos'è l'intelligenza artificiale e perché è importante per le aziende
L’intelligenza artificiale aiuta le imprese ad automatizzare attività, analizzare dati, gestire documenti e rendere più efficienti i processi. In questo articolo vediamo cos’è l’AI, come funziona e dove può generare valore reale in azienda.
Leggilo ora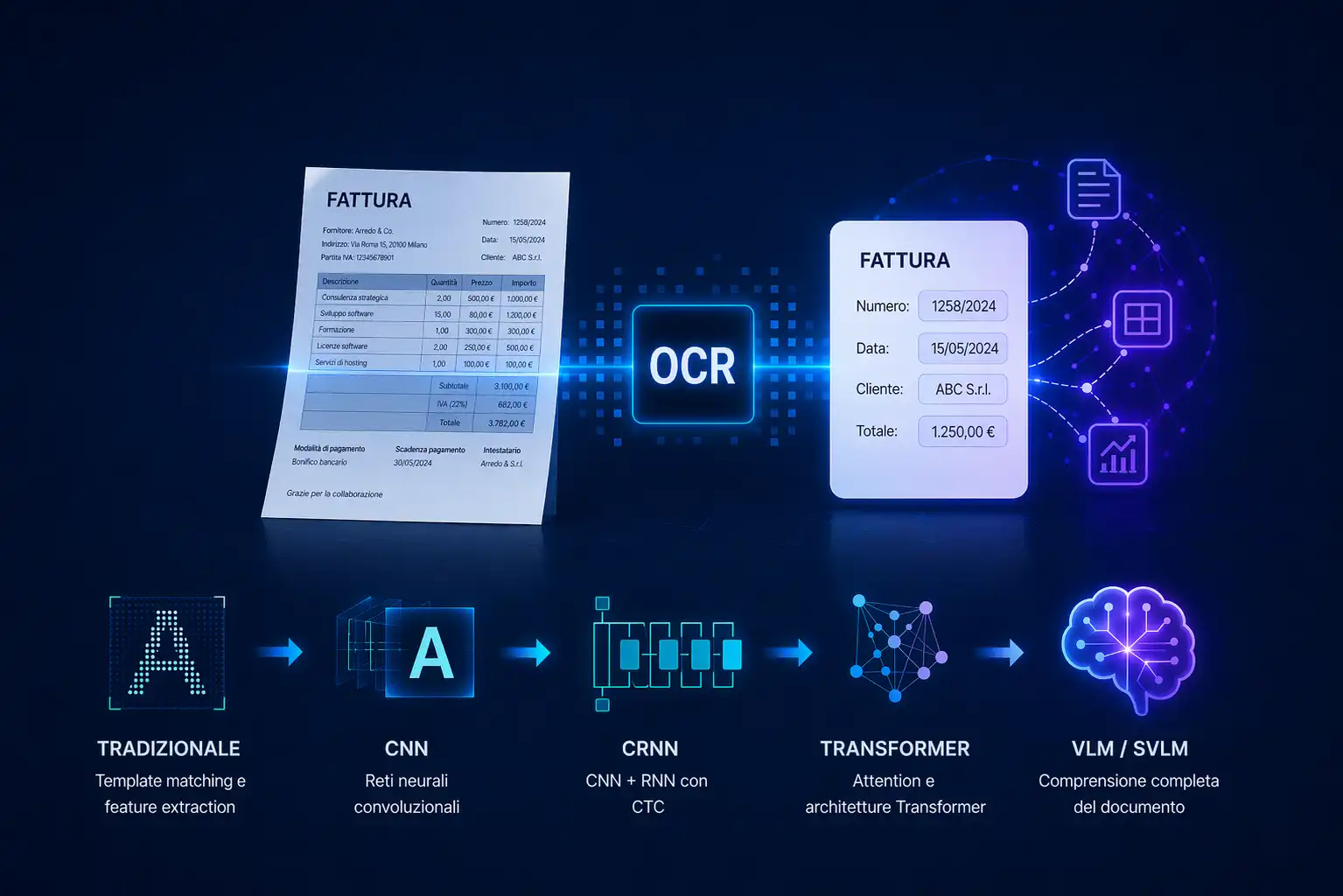
Cos’è l’OCR e come si è evoluto: dalle tecniche tradizionali ai Vision Language Model
L’OCR converte testi da immagini e PDF in contenuti digitali, ma oggi è solo il primo passo. Con VLM e IDP, i sistemi evoluti non si limitano a leggere: comprendono i documenti, strutturano i dati e abilitano l’automazione.
Leggilo ora

.svg)
.svg)
