


Structured, semi-structured and unstructured documents
The article outlines the differences between structured, semi-structured, and unstructured documents. It highlights the challenges of processing each document type and demonstrates how AI-based solutions can address these issues.
When searching for an Intelligent Document Processing (IDP) Solution, one of the first questions suppliers ask is: 'What type of document do you want to process?' The expected answer usually falls into one of three categories: structured, semi-structured, or unstructured. This article aims to clarify the differences between these document types and explore the challenges involved in extracting relevant information from each.
Structured documents
Structured documents typically follow a consistent format, with the layout and design (such as colors, fonts, and images) remaining similar across different copies. Occasionally, a structured document may undergo slight changes when a new version is released. A common example of a structured document is an identity document, where every copy adheres to the same standardized format.

This type of document is the easiest to process because the information is well-structured and consistently positioned across different samples. A common approach to processing these documents involves using traditional solutions based on rules and templates applied to the output of an OCR engine. However, this approach faces several challenges:
- Document acquisition is not always guided, leading to rotated or low-quality documents that are difficult to read and process using traditional methods.
- While structured documents are generally easy to interpret, their format can vary for several reasons, such as updates over time or differing formats across nationalities.
- Language variations within a document may require different setups for processing each version.
Semi-structured documents
Semi-structured documents contain specific types of information that are known in advance, but the position and format of this information can vary within the document. Additionally, these documents can differ significantly in layout and design, with variations in colors, fonts, and decorative elements. A classic example of a semi-structured document is an invoice. While every company is required to include certain essential information, they are free to choose the level of detail, fonts, colors, and overall configuration of the invoice. This variability makes semi-structured documents more challenging to process compared to structured documents.

Rule-based and template-based solutions for processing semi-structured documents face several problems and limitations. First, they encounter the same challenges as with structured documents. Second, semi-structured documents vary depending on the supplier, which requires the creation of a new template and corresponding rules for each variation.
Unstructured documents
Unstructured documents do not adhere to any specific format or content restrictions. A common example of an unstructured document is a contract, where the terms and conditions can vary significantly depending on the type and format of the document.

Processing this type of document is more complex than the previous categories. As a result, template-based techniques are not suitable for unstructured documents. Instead, there is a need for solutions that leverage machine learning and natural language processing to handle the variability and complexity.
You have the documents, we have the solution
myBiros is an intelligent document processing solution designed for companies facing challenges in extracting structured data from documents. Unlike traditional methods, MyBiros automates the processing of any document, extracting key information and data. This results in significant savings in time, costs, and reducing repetitive tasks for employees.
myBiros simplifies document automation through a pipeline that employs cutting-edge Deep Learning techniques. Going beyond simple OCR, MyBiros can interpret embedded data, enabling companies to manage risks, make informed decisions, and seize new opportunities. Unlike traditional rule- or template-based solutions, myBiros is fully data-driven. Its pipeline is trainable on any vertical domain without the need for predefined rules or domain-specific configurations.
By leveraging Computer Vision and NLP techniques, myBiros interprets documents based on their various characteristics - text, layout, and the document's image. As a result, myBiros is capable of processing any type of document, whether structured, semi-structured, or unstructured
Want to learn more about our solutions? Contact us today, we’re here to help!
Articles in the same category

Beyond the Demo: The Hidden Complexities of Training and Validating VLMs for Document AI
Training a VLM for Document AI may look straightforward in a demo, but bringing it into production requires a robust pipeline: multimodal datasets, controlled fine-tuning, and reliable output validation.
Read it now
Make or buy in IDP: how to choose the right document automation solution
Build or buy an IDP platform? a practical guide to assessing costs, timelines, scalability, and risks when choosing the best document automation solution.
Read it now
OCR vs IDP: differences and which technology to choose
OCR and IDP are two key technologies for document automation: OCR makes it possible to read text from images and PDFs, while IDP understands document content and transforms it into structured data ready for business processes.
Read it now
What Is Document AI? Its Evolution Over the Years and Main Tasks
Document AI represents the evolution of technologies designed to understand, classify, extract, and generate data from documents, from rule-based systems to multimodal models and complete IDP platforms.
Read it now
What is artificial intelligence and why is it important for businesses
Artificial intelligence helps businesses automate tasks, analyze data, manage documents, and make processes more efficient. In this article, we explore what AI is, how it works, and where it can generate real value within a company.
Read it now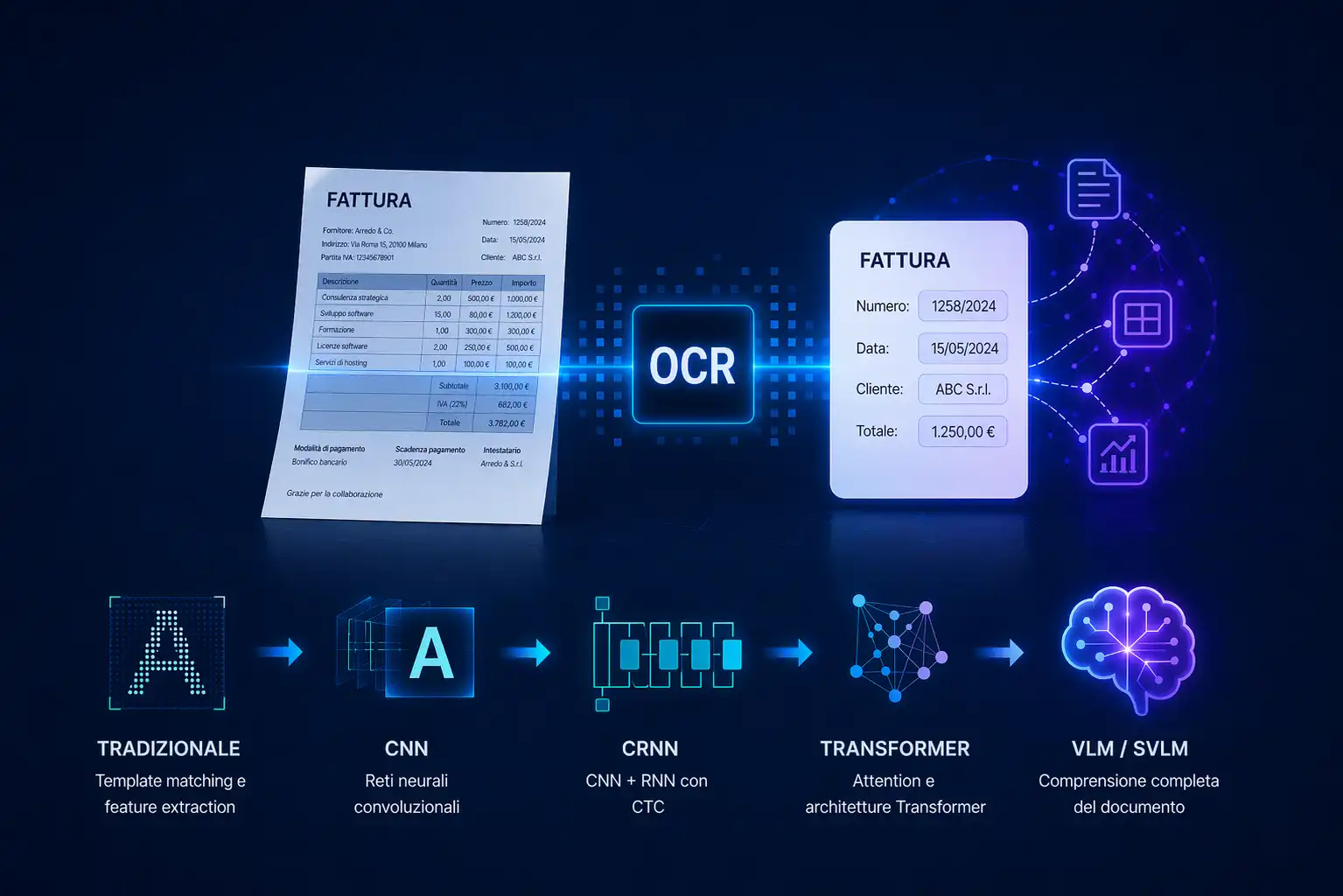
What is OCR and how has it evolved: from traditional techniques to Vision Language Models
OCR converts text from images and PDFs into digital content, but today it's only the first step. With VLM and IDP, advanced systems don't just read: they understand documents, structure data and enable automation.
Read it now

.svg)
.svg)
