


Information extraction: traditional vs modern solutions
The article reviews the process of extracting information from documents, traditionally done with rigid, inefficient methods. Modern solutions, however, offer greater flexibility and adaptability across different document types.
In document processing, the task of information extraction involves identifying and entering key data from documents into computer systems. This process can be applied to any type of document: structured, semi-structured, or unstructured.
For example, when processing an invoice, the relevant information to extract includes the issuing company, the issue date, and the address. From an identity document, the extraction focuses on personal data such as name, surname, and residence.
A generic pipeline for this task consists of three steps:
- Text recognition and transcription. Identifying the position of the text and converting it into machine-readable format.
- Information analysis. Identifying the key information of interest within the text.
- Post-processing (optional).Rrefining and validating the extracted results.

Information extraction from documents is a task that spans across all sectors. Due to the significant human intervention required, solutions capable of automating or semi-automating the process have become essential.
Traditional solutions
Traditional information extraction solutions from documents rely on rule-based and template-matching approaches. In template-matching, a mask is overlaid on the document image to filter the template and highlight the values to be extracted. In rule-based approaches, information is extracted using static rules applied after processing the document with an Optical Character Recognition (OCR) system. These methods work either independently or in combination, especially with structured and semi-structured documents, but require technical teams to configure the extraction systems. This configuration is static and demands technical intervention to handle each variation or new document type.

These solutions come with significant limitations and high development and maintenance costs. Additionally, they are unable to handle unstructured documents, as it is not feasible to establish predefined templates and rules for such documents.
Modern solutions
The use of machine learning methodologies has overcome many of the limitations of traditional solutions. This paradigm shift leads to fully data-driven approaches. The development and maintenance process for these solutions follows the structure outlined in the following diagram:

A generic approach involves training a system on a large dataset of documents to acquire a broad understanding of the application domain. The goal is to develop a system that can generalize to unseen documents, eliminating the need for constant reconfiguration to handle changes in formats or new document types.
This approach shifts the cost from continuous system configuration to the collection and creation of a high-quality dataset that accurately represents the various cases within the process of interest.
Such solutions can utilize techniques from fields like Computer Vision and Natural Language Processing (NLP). The latest advancements leverage neural networks, with the best-performing architectures being transformer-based models and graph neural networks.
You have the documents, we have the solution
myBiros is a next-generation solution for automating processes involving document processing. It leverages advanced deep learning techniques to overcome the limitations of traditional solutions. MyBiros is a no-code Document AI platform, offering ready-to-use cases and the ability to set up new cases quickly with just a few sample documents.
By using myBiros, companies can significantly reduce the costs associated with traditional document processing methods. The platform provides substantial savings in time, costs, and resources. Additionally, its features minimize the expenses related to acquiring data for model training.
With Human-in-the-Loop and Continuous Learning approaches, MyBiros continuously improves model performance through human feedback, achieving unparalleled accuracy and quality in data extraction.
The myBiros approach is entirely data-driven, making the pipeline fully adaptable to specific industry needs. By integrating techniques from Computer Vision and Natural Language Processing, myBiros interprets documents based on various characteristics, including text, layout, and the document’s visual elements.
Do you want to find out more about our solutions? Contact us!
Articles in the same category

OCR vs IDP: differences and which technology to choose
OCR and IDP are two key technologies for document automation: OCR makes it possible to read text from images and PDFs, while IDP understands document content and transforms it into structured data ready for business processes.
Read it now
What Is Document AI? Its Evolution Over the Years and Main Tasks
Document AI represents the evolution of technologies designed to understand, classify, extract, and generate data from documents, from rule-based systems to multimodal models and complete IDP platforms.
Read it now
What is artificial intelligence and why is it important for businesses
Artificial intelligence helps businesses automate tasks, analyze data, manage documents, and make processes more efficient. In this article, we explore what AI is, how it works, and where it can generate real value within a company.
Read it now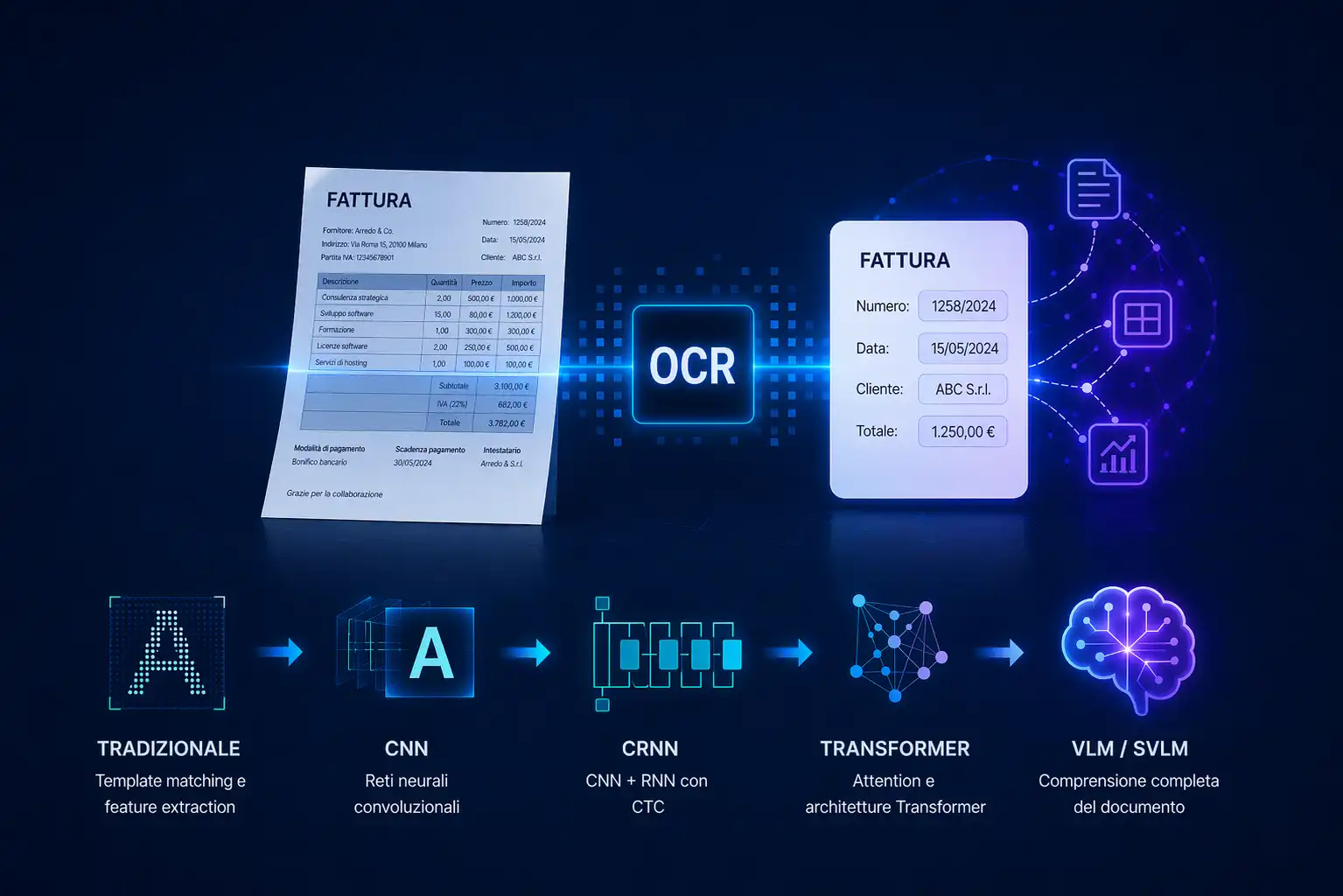
What is OCR and how has it evolved: from traditional techniques to Vision Language Models
OCR converts text from images and PDFs into digital content, but today it's only the first step. With VLM and IDP, advanced systems don't just read: they understand documents, structure data and enable automation.
Read it now
Small Vision Language Models (SVLM): what they are and why they are transforming document processing
Small Vision Language Models (SVLM) are artificial intelligence models capable of simultaneously processing visual and textual content. Born as a compact evolution of generalist VLMo, they are used in numerous domains.
Read it now
AI Agents: how to design autonomous systems with LLMs
AI agents are autonomous systems built around state-of-the-art large language models (LLMs) that go beyond answering questions—they can reason, make decisions, and complete complex workflows on behalf of the user.
Read it now

.svg)
.svg)
